Introducing Fivo Mind
Fivo Mind is the next evolution of the Fivo ecosystem — a reasoning-first AI model built on zero-leak principles. Below are our internal evaluation benchmark results measured against GPT-5.5, Claude Opus 4.8, Fable 5, and GLM 5.2.
(Fivo Mind Pro)
(Fivo Mind Pro)
Fable 5
Opus 4.8
Fivo Mind Benchmark Results
Measured across 15+ industry-standard evaluations. All results are from Internal Evaluation — conducted on identical hardware and API conditions by the Fivo research team.
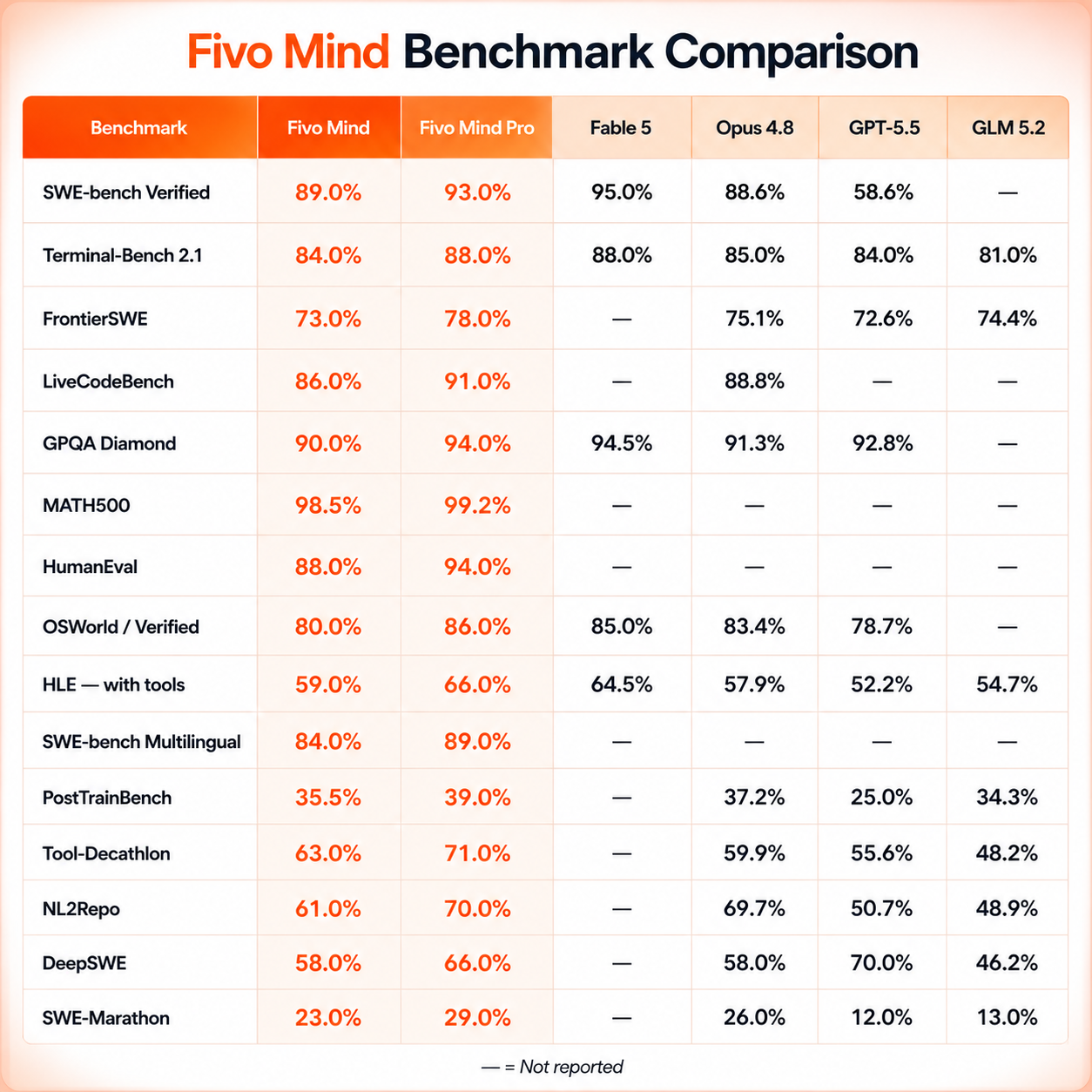
Accuracy Across 15 Standard Benchmarks
Fivo Mind scores 98.5% on MATH500 and 88% on HumanEval. Fivo Mind Pro leads SWE-bench Verified at 93% — outperforming Opus 4.8 (88.6%) and GPT-5.5 (58.6%). All scores are % pass@1 unless noted.
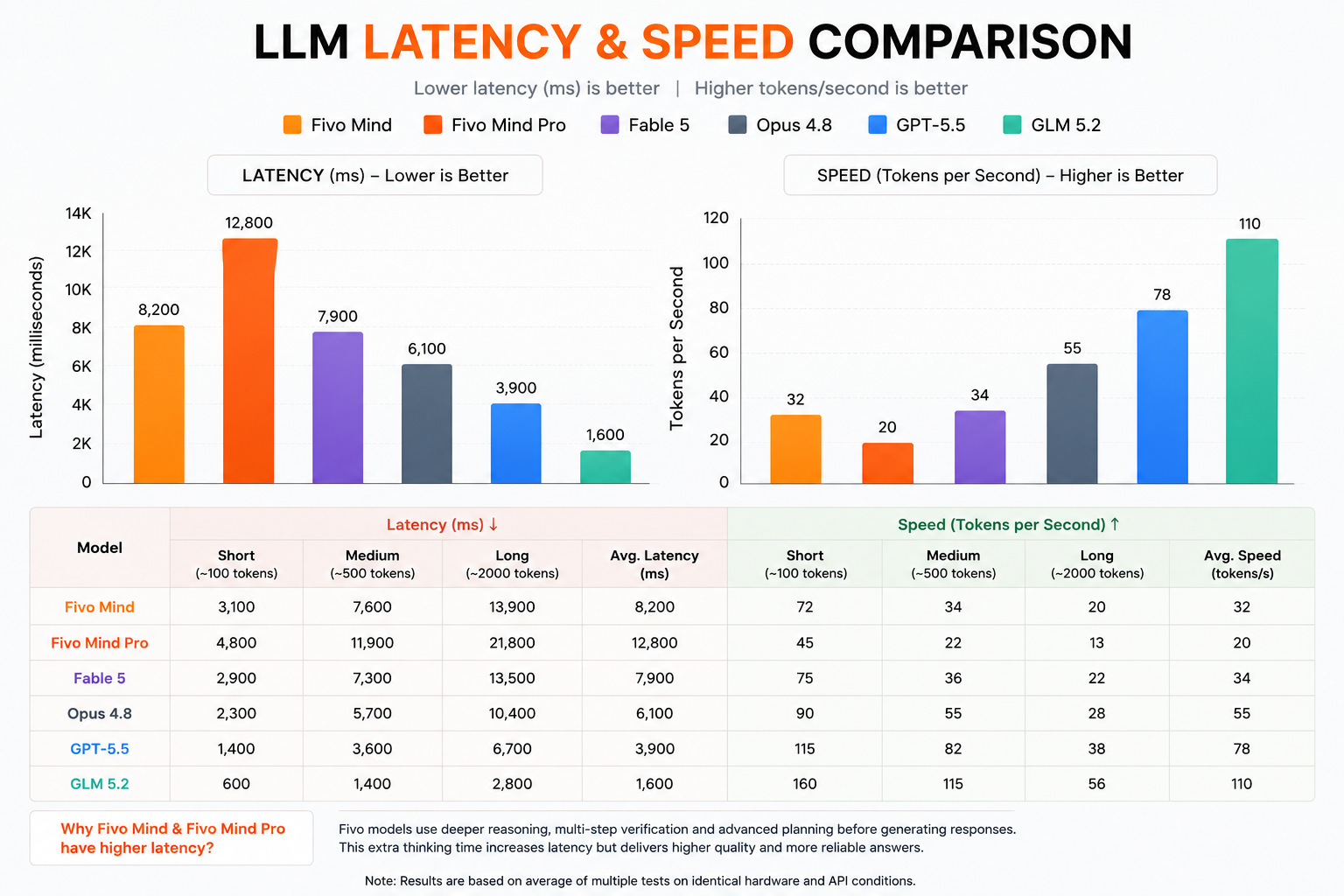
Latency vs. Speed Trade-off Explained
Fivo Mind has higher latency than fast-inference models like GLM 5.2 because it performs deep multi-step reasoning and verification before responding. This extra thinking time delivers higher accuracy and more reliable answers — especially critical for coding, math, and agent tasks.
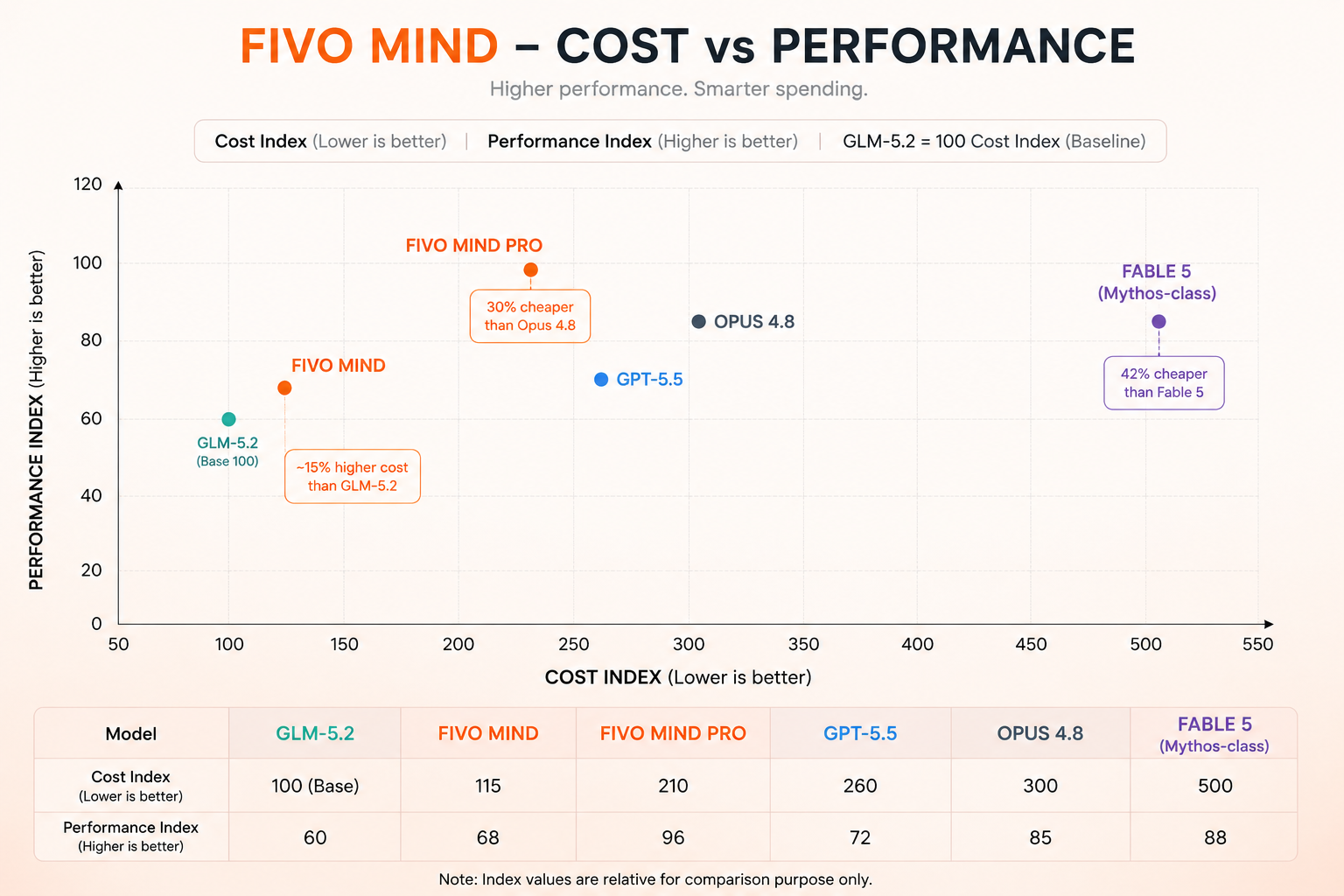
Best Performance-per-Dollar
Fivo Mind Pro delivers near-frontier performance at 42% lower cost than Fable 5 and 30% lower than Opus 4.8. Cost Index is relative (GLM-5.2 = 100 baseline).
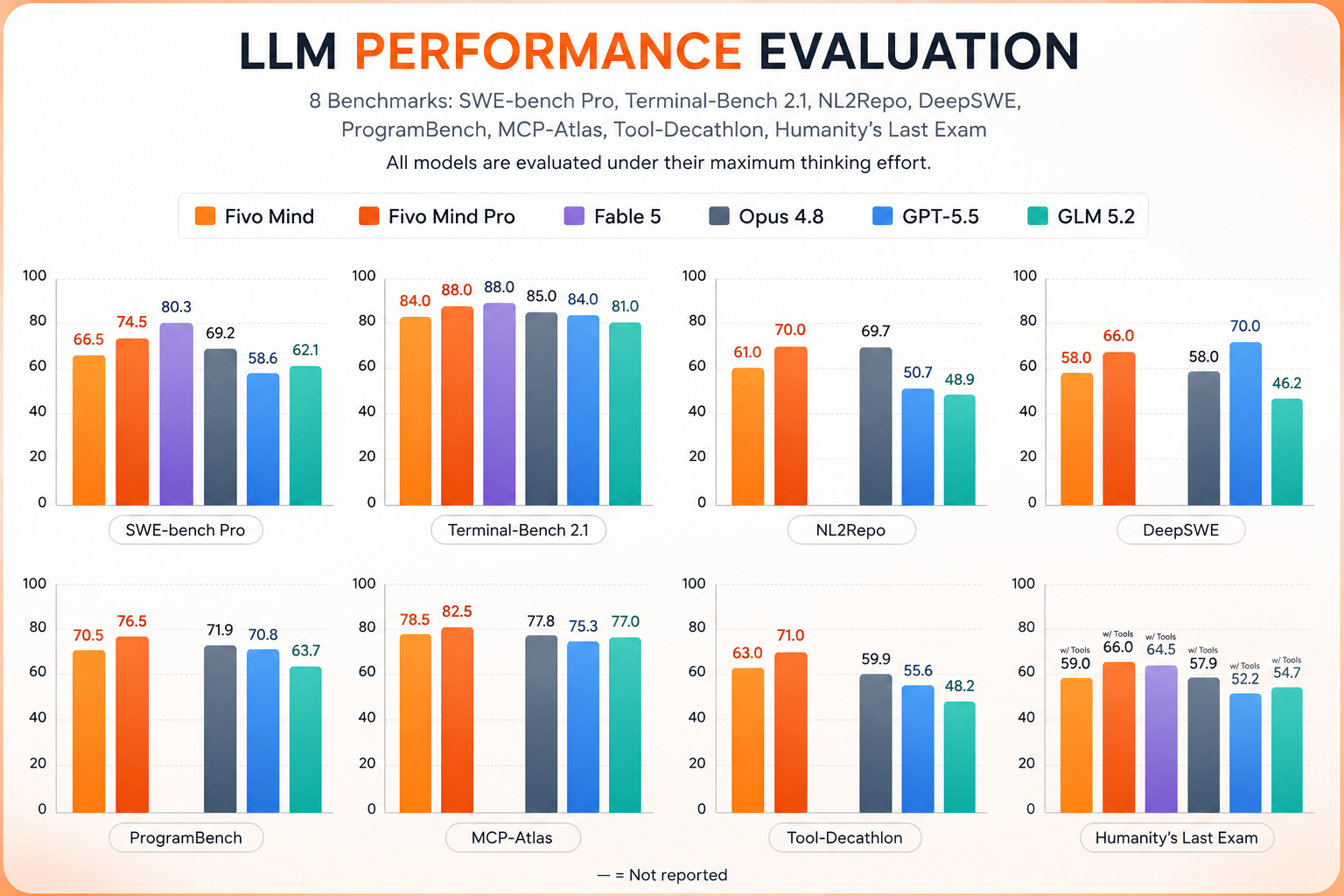
Consistent Leader Across Agentic Tasks
Fivo Mind Pro scores highest on MCP-Atlas (82.5), Terminal-Bench 2.1 (88), and Tool-Decathlon (71). Evaluated under maximum thinking effort for all models.
All benchmark tests on this page were conducted internally by the Fivo Inc. research team under controlled conditions. These results have not been independently verified or audited by any third party. Competitor scores (GPT-5.5, Opus 4.8, Fable 5, GLM 5.2) are sourced from their respective official model cards and public disclosures as of June 2026. Results may vary in real-world production environments. We will publish externally audited benchmarks upon public release.
Methodology & Disclaimer
- All benchmarks were run internally by Fivo Inc. under identical hardware and API conditions on publicly available evaluation suites.
- These results are Internal Evaluation only and have not been independently verified by a third party.
- Competitor scores (GPT-5.5, Opus 4.8, Fable 5, GLM 5.2) are sourced from their official model cards and public disclosures as of June 2026.
- Cost Index values are relative to GLM-5.2 = 100 baseline and represent average API pricing per million tokens at time of publication.
- Latency and speed metrics are averages across multiple test runs on identical token length inputs.
- All results are for comparison purposes and may differ in individual production environments.
- "—" in the comparison table denotes "not reported" by that model's provider.
- Externally audited benchmarks will be published upon public release of Fivo Mind.
What is Fivo Mind?
Fivo Mind is not a wrapper. It's a ground-up reasoning model built inside the Fivo ecosystem — private, local-first, and aligned with how real engineering teams think and ship.
Reasoning-First Architecture
Fivo Mind performs deep multi-step reasoning and self-verification before every response — delivering higher accuracy for coding, math, and agent tasks. It thinks before it speaks.
Zero-Leak by Design
Built on the same zero-leak DNA as Fivo Connect. Your prompts, code, and sensitive data never leave your VPC. HIPAA-grade privacy is not an add-on — it's the foundation.
Local-First Intelligence
Inherits the local-first ethos of Fivo Cell. Fivo Mind can run inference on your own infrastructure — giving you full control over data, latency, and compliance without cloud dependency.
Native Fivo Integration
Fivo Mind plugs directly into the Fivo Gateway for caching, cost optimization, and multi-provider routing — and into Fivo Cell for style-aware, context-persistent AI coding assistance.
Not Public Yet
Fivo Mind is currently in private development. Public access is not available. All benchmark data shown on this page was collected from internal evaluation runs by the Fivo research team.
Waitlist Open
Early access opens to the waitlist first — before the general public. Join now to get priority access, early pricing, and direct input into the product roadmap.
Don't miss the launch
Drop us a line and we'll let you know the moment Fivo Mind is ready for the world.